 Python, Django (2014 – 2016)
Python, Django (2014 – 2016)
Veritza is a prototype of a tool for automated data collection of public records. The tool experimented with the idea to automate the discovery of story leads from public records by scraping, ingesting and aggregating data, and analyzing it for patterns and anomalies, with the aim to help reporters more find story leads more easily from public records.
URL: http://veritza.herokuapp.com/
Github repo: https://github.com/padejski/veritzaproto
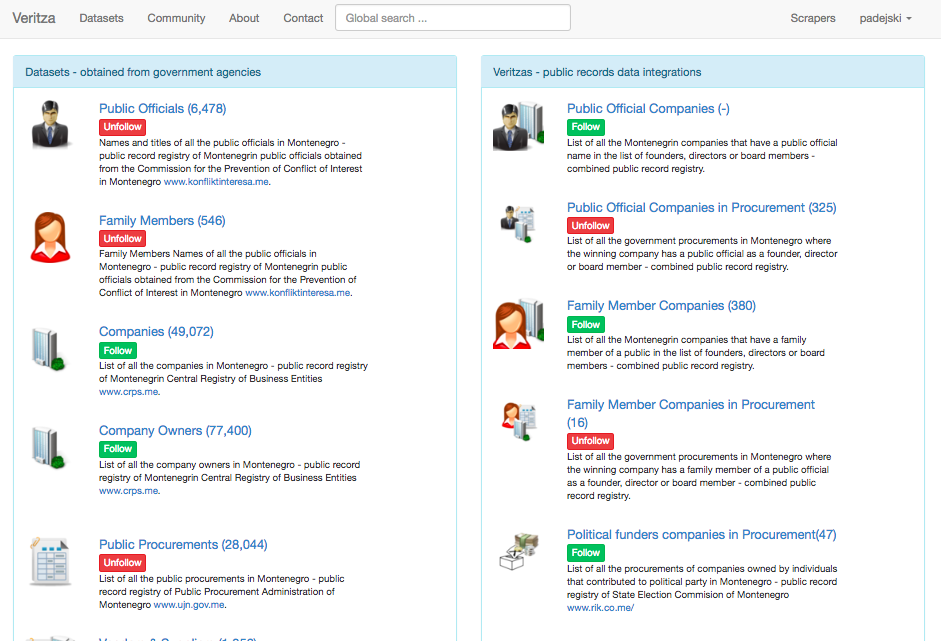
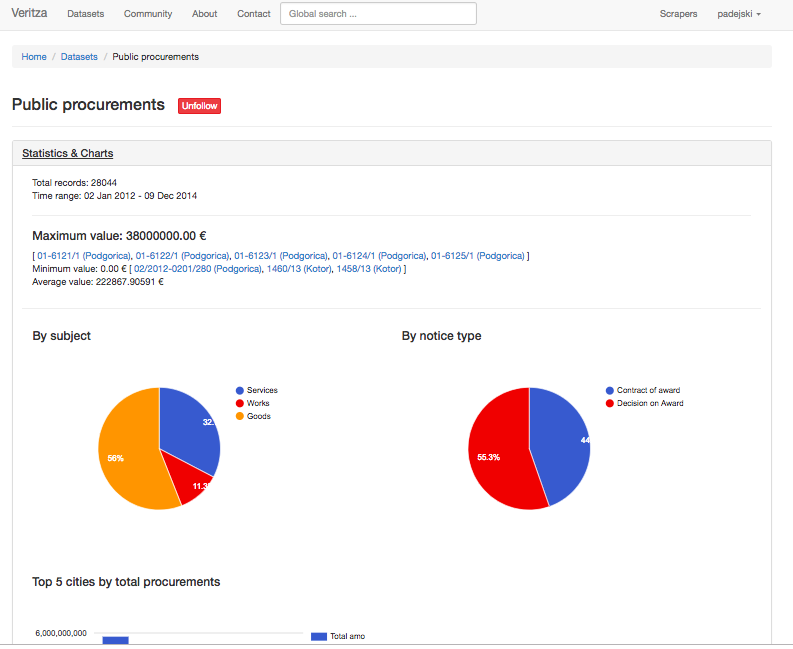
The project focused on a selective list of public records and scenarios that have already proven themselves to be practical in identifying story leads on corruption and other wrongdoings. It went beyond simply serving collections of data by providing common analyses, summaries, and real-time alerts. Veritza’s emphasis was exploring the news discovery problem, rather than data access or standards issues. The design of this project sought to match the needs of journalists and to apply the editorial and investigative experience using data – all in an automated fashion.
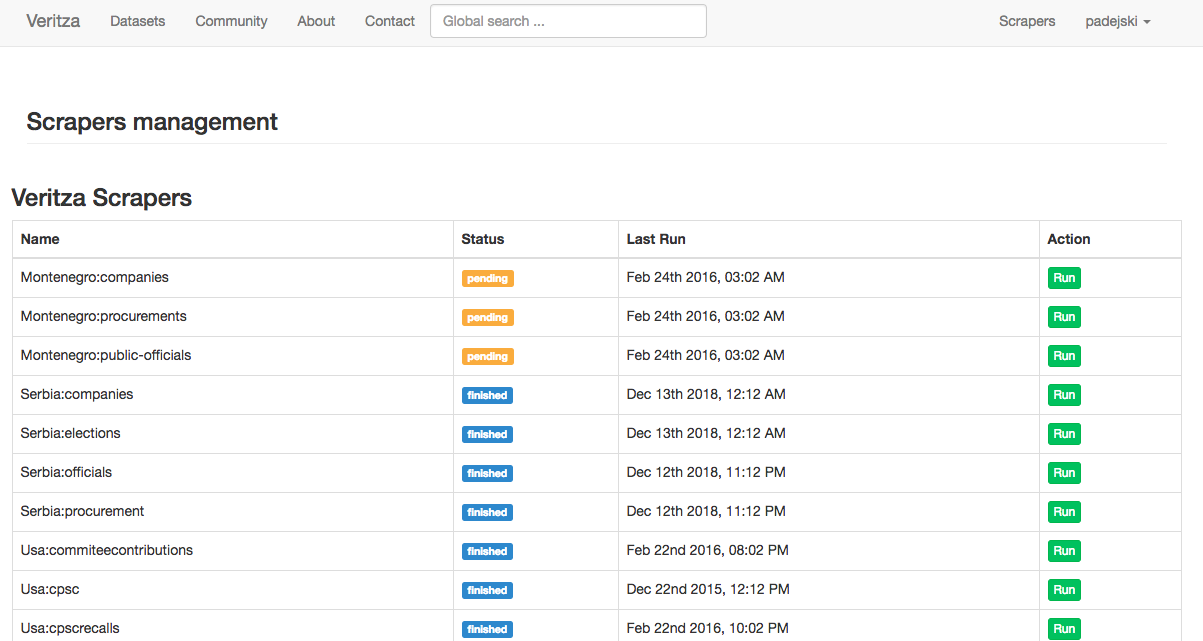
The working prototype of the tool, used experimental instances to produce alerts over twenty government dataset sources: Federal Procurement Data System, Federal Election Commission, SEC Edgar, The Clerk of the House, IRS Exempt Organizations, EPA Toxics Release Inventory, OSHA Workplace Safety Data, Consumer Product Safety Commission, CA Campaign finance, California Fair Political Practices Commission, CA Department of General Services Procurement Division. Alerts were delivered to test users in form of email reports.
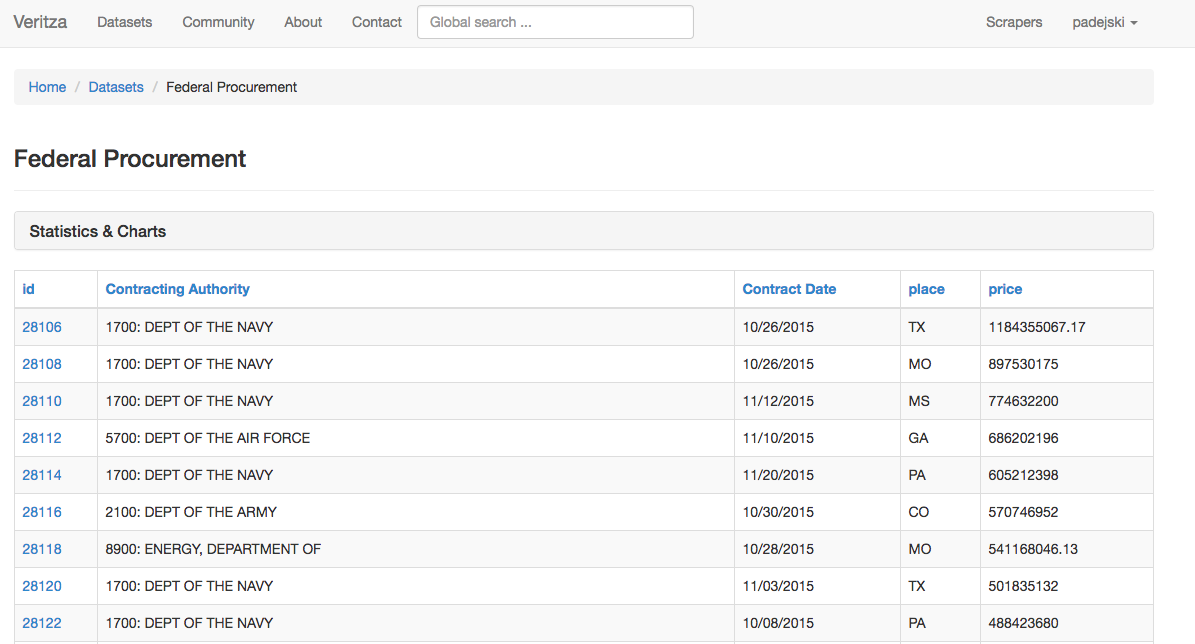
The system demonstrated this concept on a small set of repositories, but the server costs were too high for a nonprofit initiative, so the project is available online but the datasets are not being updated in real-time.